![]()
Predicting Building Code Compliance
with Machine Learning Models
Here on the Data Analytics team at Azavea, we partner with government agencies, non-profits, and private companies to develop data tools that inform decision-making. We feel that government agencies and non-profits can make significant improvements through the use of machine learning. Machine learning models are sophisticated tools that these organizations can use to transform their wealth of raw data into useful intelligence. They can help guide decision-makers in allocating limited resources to solve urban problems ranging from crime, to aging infrastructure, to traffic congestion.
We have built a proof of concept model that seeks to address one of these problems: building safety. The objective is to answer the question of which buildings inspectors should prioritize in order to maximize public safety? This site contains a detailed description of our model and process for building it.
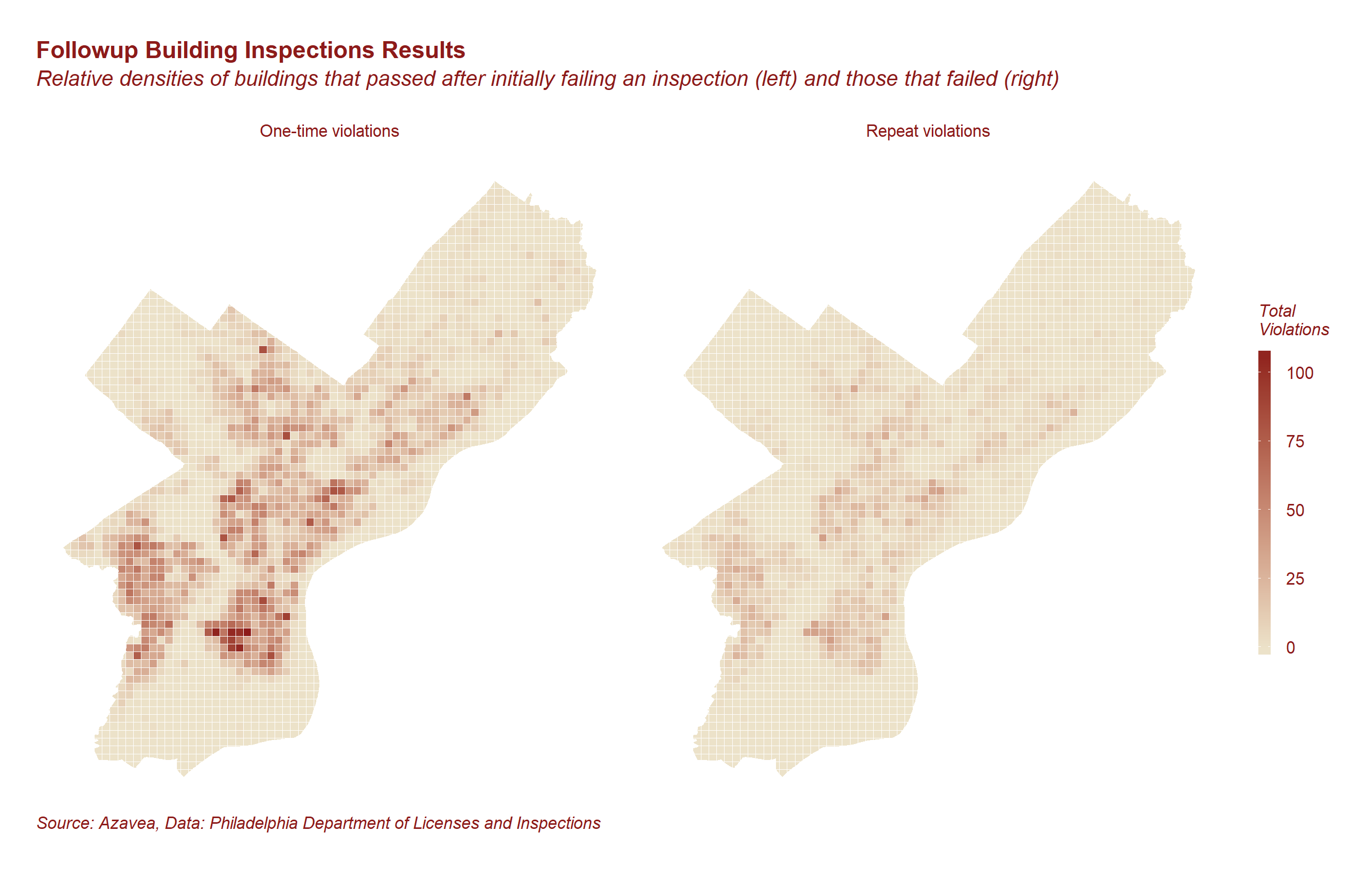
We have divided this write-up into four sections: data pre-processing, feature selection, model building and finally, results. In addition to code snippets and annotation, these sections each include images and plots that help give a full picture of the process.
This site is meant to be fairly technical. For a higher level look at the project, check out its write-up on the Azavea blog. If you would like to replicate this analysis, feel free do download the repository.
This project was completed by the Data Analytics Team at Azavea. The data we used came from the City of Philadelphia Departments of Licenses and Inspections, Revenue, and Innovation and Technology. We conducted the analysis using R and made use of the following packages: dplyr, tidyr, ggplot2, data.table, magrittr, sp, rgdal, lubridate, plyr, forcats, caret, spatstat, RCurl, jsonlite, Boruta, pROC, statmod, h2o, sf, ggjoy, plotROC, ggpubr, waffle and svglite.